Member-only story
Mastering Random Forest Algorithm: A Step-by-Step Learning Guide
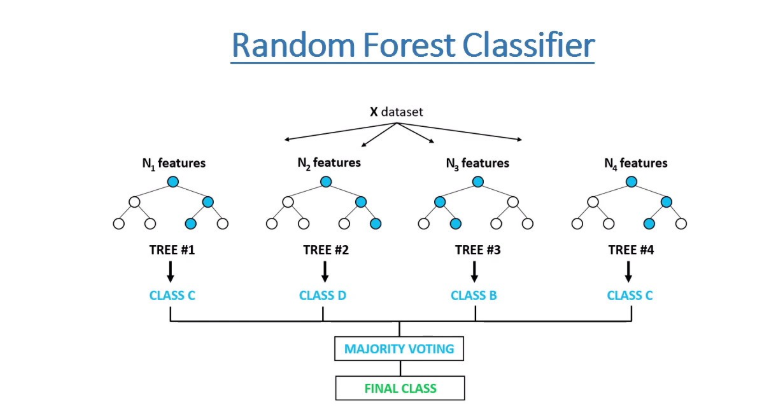
What is Random Forest?
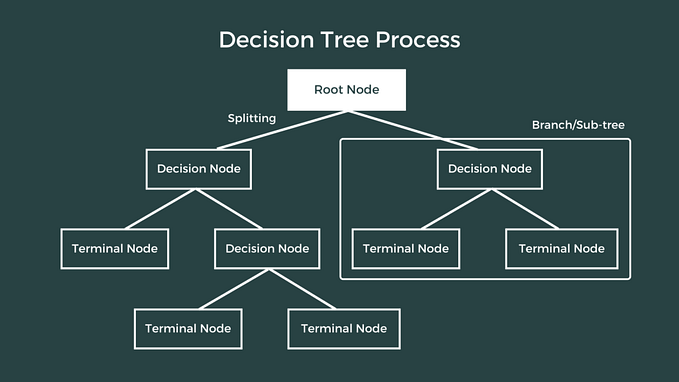
Random Forest is a popular machine-learning algorithm used for both classification and regression tasks. It is an ensemble learning method that combines multiple decision trees to make a final prediction.
The basic idea behind the random forest algorithm is to create a large number of decision trees and then combine their predictions to obtain a more accurate and stable result. Each decision tree in the forest is trained on a random subset of the data and a random subset of the features, which helps to reduce overfitting and improve the generalization ability of the model.
When making a prediction, the random forest algorithm aggregates the predictions of all the decision trees in the forest to make a final prediction. The most common approach is to use majority voting for classification tasks and averaging for regression tasks.
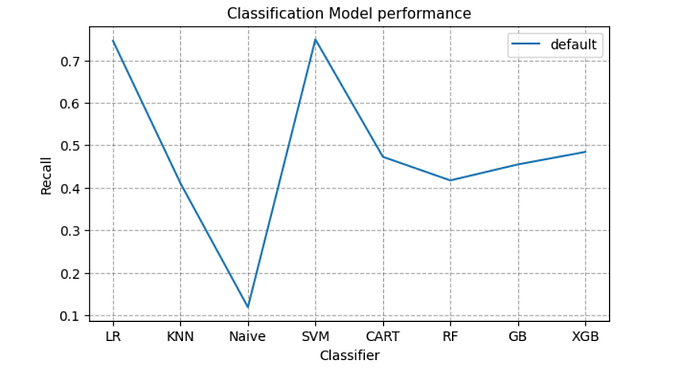
The randomforest has several advantages over single decision trees, such as improved accuracy, reduced overfitting, and better handling of noisy and missing data. It is widely used in a variety of applications, including finance, healthcare, and natural language processing.
Why do we use Random Forest?
Random Forest is a popular machine learning algorithm for several reasons:
- High accuracy: Random Forest has been shown to be highly accurate in a wide range of applications, particularly when compared to single decision trees.
- Robustness: Random Forest is less sensitive to noise and outliers in the data, as it aggregates the predictions of many individual decision trees, rather than relying on a single tree.
- Scalability: Random Forest can handle large datasets with many features and observations, making it suitable for a wide range of applications.
- Interpretability: Random Forest provides information on the relative importance of different features in the data, making it easier to interpret and understand the model.
- Flexibility: Random Forest can be used for both classification and regression tasks, and can handle both categorical and continuous data.