Member-only story
Step-by-Step Guide to the KNN Algorithm: Understanding the Fundamentals and Applications

KNN (K-Nearest Neighbors)
The K-Nearest Neighbors (KNN) algorithm is a popular supervised learning algorithm used for classification and regression tasks.
The KNN algorithm is based on the principle that objects or data points that are close to each other in feature space are likely to belong to the same class or have similar outputs. The KNN algorithm assigns a new data point to the class that is most common among its k nearest neighbors. The value of k is a hyperparameter that needs to be specified before the model training.
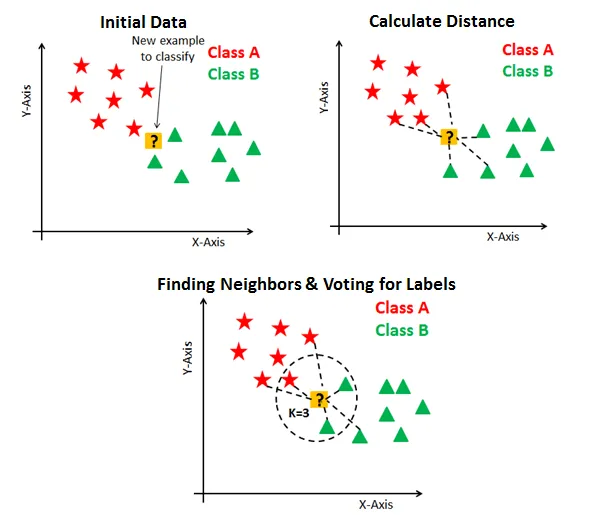
Here are the main steps involved in the KNN algorithm:
- Calculate the distance between the new data point and all the training data points based on a distance metric such as Euclidean distance or Manhattan distance.
- Select the k nearest neighbors based on the smallest distances.
- Assign the new data point to the class that is most common among its k nearest neighbors for classification tasks or predict the output as the mean of the k nearest neighbors for regression tasks.
- Evaluate the performance of the model using a suitable metric such as accuracy or mean squared error.
- Tune the hyperparameters of the model such as the value of k using a validation set or cross-validation.
The KNN algorithm is simple to understand and implement and can work well for small datasets. However, it can become computationally expensive for large datasets and high-dimensional feature spaces.
Example Of KNN
Let me give you a real-time example of the KNN algorithm with calculations.
Suppose we have a dataset of 10 observations with two features, height and weight, and a binary target variable, gender. We want to predict the gender of a new observation with a height of 175 cm and weight of 75 kg using the KNN algorithm.
